雖然是回歸,但實際上是處理分類問題的,邏輯回歸通常用於判斷二元分類問題
例如有沒有人、是不是垃圾郵件、有沒有感染病毒等等。
基本上是計算sigmoid function進行分類。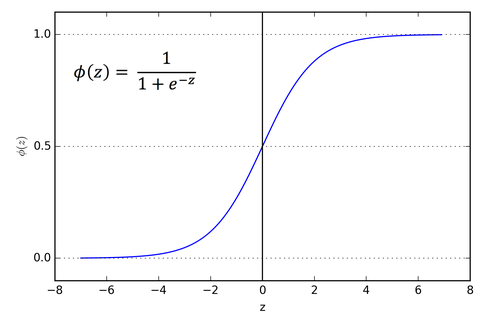
其中我們要做的是擬合z值,z=b+w1x1+w2x2…..,計算特徵權重
訓練好的模型,在判斷圖片時,會計算出z值代入sigmoid function中
計算出來的y值會落在0到1之間,可以透過這個y值來進行分類
例如算出來y=0.7,可以表示為70%機率有人,也可以單純轉換成二分法類別,有人。
誤差的計算方式是採用LogLoss 
可以用存款金額(特徵)與會不會買車(預測目標)來進行思考理解
Threshold(閥值):指定正負類別如何分界,在此值以上為一類,此值以下為一類。
真值(True)假值(False):預測對或錯
正類別(Positive)與負類別(Negative):定義的兩種類別標籤
可以定義出四類
True Positive 正類別(原本)正類別(預測)…預測成功
True Negative負類別(原本)負類別(預測) …預測成功
False Positive 負類別(原本)正類別(預測) …預測失敗
False Negative正類別(原本)負類別(預測) …預測失敗
Accuracy(準確率)=(TP+TN) / ALL
正確的預測佔總體預測多少比例->預測對的機率有多高
Precision(精確率)=(TP)/(TP+FP)
預測對的正類別佔所有被預測成正類別的比例->說是正類別時實際上也是正類別的機率
Recall(召回率) =(TP)/(TP+FN)
預測對的正類別佔所有正類別的比例->正類別被正確辨識的機率
邏輯回歸預測的預測平均值應該要約等於觀測平均值
當這兩者間的差值太高,代表模型有問題
問題發生的原因可能是


 iThome鐵人賽
iThome鐵人賽